About
The Scholarly Ontologies (ScholOnto) Project was funded by the EPSRC Distributed Information Management Programme (2001-2004). The goal was to build and deploy a prototype infrastructure for making scholarly claims about the significance of research documents. ‘Claims’ were made by making connections between ideas. Any claim is of course open to counterarguments. The connections were grounded in a discourse/argumentation ontology, which enabled innovative services for navigating, visualizing and analysing the network as it grows.
The prototype was called ClaiMaker, which led subsequently to the Cohere web annotation platform.
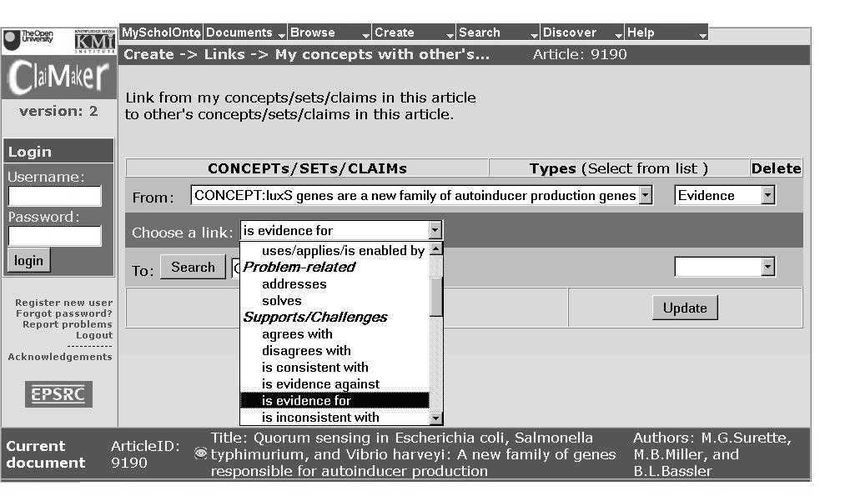
ClaiMaker enabled distributed modelling of documents in a literature, and provided a variety of services for browsing and analysing the emergent conceptual graphs. The ClaiMaker forms interface (above) was for creating a claim. The bottom bar gave details of the paper the reader was modelling. The user has already selected the concept to be linked from and given it the optional type ‘ Evidence ‘. They have selected a link from the drop down list of options. The next step would be to select the search button to look for the third component of the Claim triple.
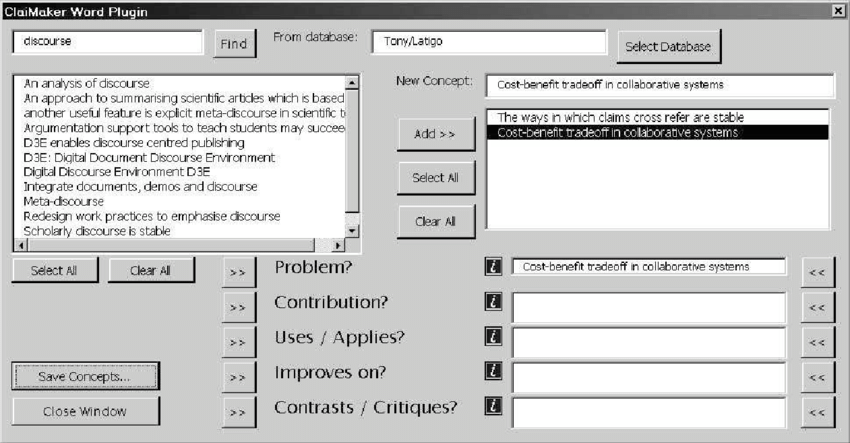
ClaiMaker Word plug-in (above). Existing Concepts on the web server could be searched and displayed in the panel top left. New concepts were displayed on the right and were assigned types using the five prompts in the lower part of the screen.
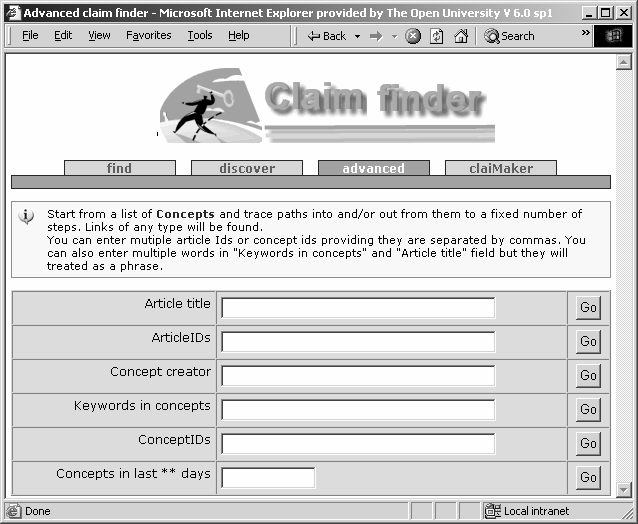
ClaimFinder generated interactive visualisations of argument structures in response to queries. ClaimFinder, delivered services as tabs on a web page, rather than as items embedded in a drop-down menu in ClaiMaker. The default page provided a simple, single-field form for users to do keyword searching, with ‘advanced’ search tabs delivering encapsulated services.
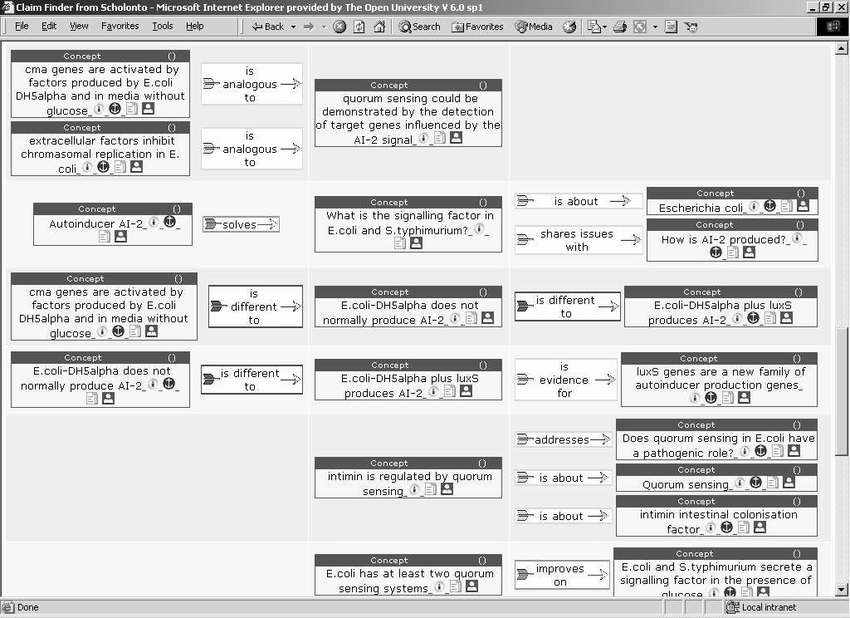
In this rendering, a three-column tabular layout shows each Concept/Set in the search results, with incoming and outgoing links to Concepts/Sets in the left and right columns. This example is taken from modelling part of the test dataset released from the Proceedings of the National Academy of Sciences, as part of a domain visualisation symposium (Shiffrin and Borner, 2003).
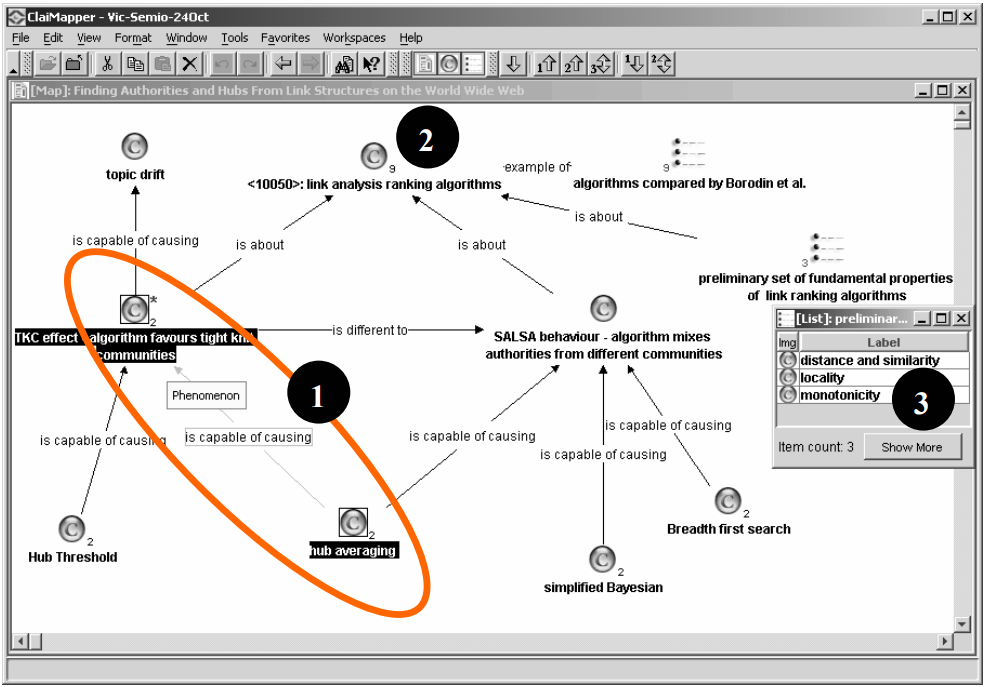
ClaiMapper was a standalone tool, based on the Compendium visual hypertext system (Selvin and Buckingham Shum, 2002). Instead of filling in a new form for each bipartite connection, the user could simply draw links between nodes, specifying the link type when prompted. Users could search the ClaiMaker server for existing concepts match a selected node in a map, and import or simply drag and drop search ‘hits’ directly into ClaiMapper, creating nodes with full database metadata, ready to be reused through connection to new structures. ClaiMapper was proven to be a significant advance in supporting the cognitive demands of modelling, seeing the ‘bigger picture’, more rapidly creating claim structures, and the tool was used for analysis and note-taking without ever uploading the model to the server. Sketching ClaiMaker compatible models using the ClaiMapper tool.
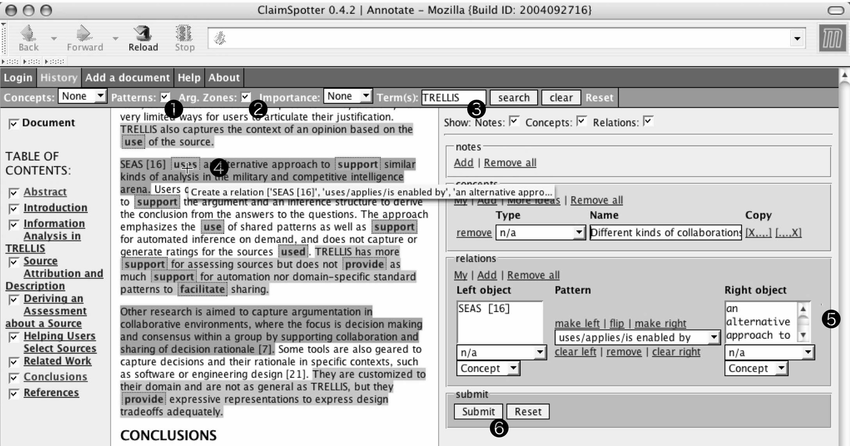
The ClaimSpotter interface helped the user focus on subsets of the original text. In the example above, the user has combined the candidate relations, the rhetorically-coherent areas and a user-defined filter to help focus on subsets of the original text which are deemed interesting. Candidate relations found could be clicked on and split into claim triples and submitted immediately to the database if desired.
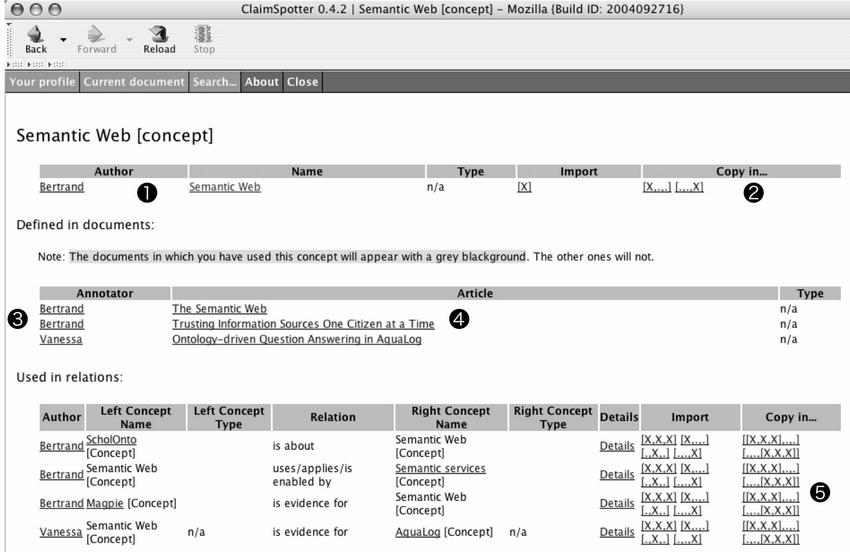
The user could access a History window for a Concept which displayed, for instance, the author and the different uses of that Concept over the corpus of documents. It could be copied in the current document with a single click, if a user decided so. In a similar way, the different relations in which it was used could be imported into the document that was being annotated, or copied in order to discuss them. Multiple links within the History window allowed a quick navigation within the annotation repository.
Team
Principal Investigator: Simon Buckingham Shum
Co-Investigators: John Domingue, Enrico Motta
Research Fellows: Gangmin (Gary) Li, Victoria Uren
Related PhDs: Clara Mancini, Bertrand Sereno, Murray Altheim, Neil Benn
Publications
Buckingham Shum, S. (2006) Sensemaking on the Pragmatic Web: A Hypermedia Discourse Perspective, PragWeb’06: 1st International Conference on the Pragmatic Web, Stuttgart, KMI Technical report 06-16
Mancini, C. and Buckingham Shum, S. (2006) Modelling Discourse in Contested Domains: A Semiotic and Cognitive Framework, International Journal of Human Computer Studies, 64, 11, pp. 1154-1171, KMI Technical report 06-14.
Buckingham Shum, Simon J.; Uren, Victoria; Li, Gangmin; Sereno, Bertrand and Mancini, Clara (2007). Modelling naturalistic argumentation in research literatures: representation and interaction design issues. International Journal of Intelligent Systems, 22(1) pp. 17–47.
Uren, Victoria; Buckingham Shum, Simon; Bachler, Michelle and Li, Gangmin (2006). Sensemaking tools for understanding research literatures: design, implementation and user evaluation. International Journal of Human-Computer Studies, 64(5) pp. 420–445.
Mancini, C. & Buckingham Shum, S., (2006) Modelling Discourse in Contested Domains: A Semiotic and Cognitive Framework. International Journal of Human Computer Studies, Vol.64, 11, (1154-1171).
Buckingham Shum, Simon; Uren, Victoria; Li, Gangmi; Domingue, John and Motta, Enrico (2003). Visualizing internetworked argumentation. In: Kirschner, Paul A.; Buckingham Shum, Simon J. and Carr, Chad S. eds. Visualizing Argumentation: Software Tools for Collaborative and Educational Sense-Making. Computer supported cooperative work. London: Springer-Verlag, pp. 185–204.
Buckingham Shum, Simon; Motta, Enrico and Domingue, John (2000). ScholOnto: an ontology-based digital library server for research documents and discourse. International Journal on Digital Libraries, 3(3) pp. 237–248.




