About
OmniVoke was a framework that aimed at automating the invocation of generic Web APIs. The framework provided a unique entry point for the invocation of most Web APIs that could be found on the Web. The framework thus abstracted away the heterogeneities of different APIs and consequently eliminated the need for developing a custom-tailored client per Web API. The framework relied on non-intrusive semantic annotations of HTML pages describing Web APIs, in order to capture both their semantics as well as the information necessary to carry out their invocation.
The framework was implemented following RESTful principles to simplify its use and to adequately exploit the Web infrastructure for scalability. It included a RESTful interface enabling the invocations as well as the monitoring or post-mortem analysis of API execution by publishing associated artifacts generated or used during the interaction with remote APIs, such as messages exchanged, etc.
Why
Despite their increasing popularity, Web APIs were most often described solely through HTML Web pages that were designed for humans and posed outstanding difficulties for their automated identification and interpretation in order to support, for example, automated Web API discovery and invocation. The use of Web APIs still required therefore extensive manual effort, which involved developing custom-tailored client software.
The platforms that provided machine-readable metadata about APIs, thus enabling the auto-generation of client software, such as the Google APIs Discovery Service and the Mashery API test invocation, supported only a predefined set of APIs and provided very limited coverage.
Technologies
Automating the invocation of Web APIs, as to their other tasks, relied on semantic extensions to service properties. Minimal Service Model was a simple RDF(S) ontology that was designed to capture the core semantics of both “classical” Web services and Web APIs in a common model. In its initial design, it provided support for service publishing and discovery. Yet, it permitted extensions when such a need arose, such as invocation. The Extended Minimal Service Model, with which OmniVoke worked, extended the initial model with invocation-specific service descriptions. In particular, the model defined input data grounding, which specified whether the input values were transmitted as part of the URI, HTTP headers, or the HTTP request message body (applicable to HTTP POST and PUT requests), as well as the message format when input was transmitted as message body.
It was important to point out that a majority of Web APIs required some form of authentication featuring three main characteristics, i.e. the required credentials, the authentication protocol used, and the way of sending the authentication information. We developed an authentication ontology that enabled the annotation of authentication information as part of a semantic Web API description so that authentication could be seamlessly handled by OmniVoke.
Framework
With data sources on the Web undergoing a developing trend towards Linked Data, Web APIs, which provided on-the-fly computation of data resources through invocation, needed to progress in order to continue playing their roles as Linked Data prosumers when invoked through semantic extensions. Therefore, OmniVoke took RDF data as input and returned RDF data as response data, thus enabling a seamless integration of Web APIs, as semantic data prosumers, into the linked data space. To carry out concrete invocations, the envisaged scenario was for applications to issue SPARQL queries to derive the data required for invoking a particular Web API. Alternatively, appropriate user-interaction interfaces could be provided to allow the user to provide his/her input, which, together with response data, could be collected into shared data space for further manipulations like inspection, re-use, etc. In the latter case, the user was typically presented with a set of input fields, which needed to be completed in order to invoke the service. Semantic annotations or descriptions of the service could be attached to aid the user. Additional information such as comments could be provided to support the user in resolving any potential ambiguities. OmniVoke supported both means of deriving request data.
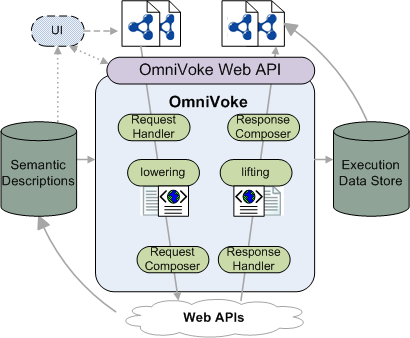
Request Handler
Validated the request to OmniVoke, extracted information related to the invocation request to the actual API by interpreting the API’s semantic descriptions.
Lowering
Using the lowering script given in the semantic description, it undertook the task of “lowering” RDF input data to the format supported by the actual API.
Request Composer
Constructed a valid request for invoking the actual Web API using information provided in the service description and the “lowered” input.
Response Handling
De-capsulated the API response, i.e., extracted the status code, response data, out of response headers, body, etc., and decided whether lifting was required for each output, with the help of the service description.
Lifting
Using the lifting script given in the semantic description, it undertook the task of “lifting” the output data in the format prescribed by the actual API to RDF output.
Response Composer
Constructed a valid response to the original OmniVoke request using information given in the service description and the “lifted” output.
Authentication Ontology
Authentication of Web APIs had three main characteristics: 1) the required credentials, 2) the authentication protocol used, and 3) the method of sending the authentication information, which were described as three classes in the proposed authentication ontology: AuthenticationMechanism, Credentials, and TransmissionMedium, respectively. The ontology was shown below. The AuthenticationMechanism class had six subclasses corresponding to six types of common authentication mechanisms. AuthenticationMechanism was associated with the concept of either Service or Operation through the hasAuthenticationMechanism property.
It related to Credentials and TransmissionMedium through the properties of hasInputCredentials and wayofSendingInformation, respectively. The Credentials class had several subclasses, including APIKey, Username, Password, etc., required by different authentication mechanisms. TransmissionMedium had three instances (ViaHTTPHeader, viaHTTPBody, and ViaURI), used to describe that the credentials were sent using only the URI or through constructing an HTTP header.
Authentication Mechanisms
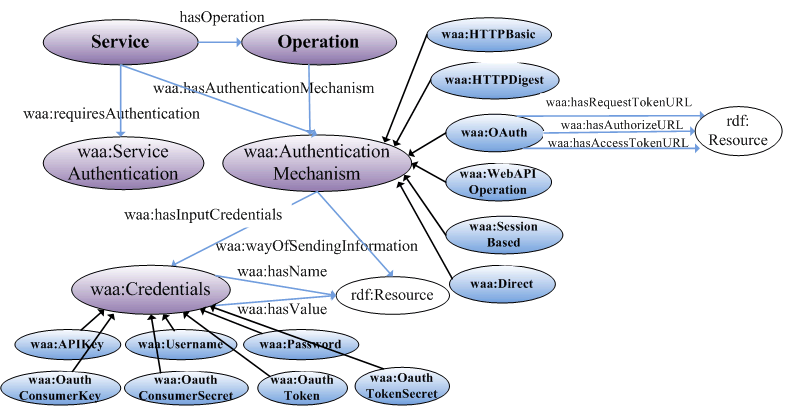
The authentication mechanisms used by most Web APIs were differentiated by either the authentication credentials used (e.g., API key or username and password), the transmission security protocol (HTTP Basic Authentication, HTTP Digest Authentication, and OAuth), or a combination of those. In the authentication ontology, they were classified into the following six types, which were described as RDF(S) classes.
Direct
The Direct class was used to describe the authentication mechanism that employed no transmission security protocol and relied only on credentials. Typically, the credentials used in this type of authentication mechanism were API Key or username and password, which were described in APIKey, Username, and Password classes as subclasses of Credentials. The actual string name used by each API to represent every type of credential was an instance of the corresponding type, for example, “api_key”, “APIKey” were instances of class APIKey.
HTTPBasic
The HTTPBasic class described the basic access authentication mechanism that accompanied the HTTP/1.1 specification. It required a username and password as credentials when making an HTTP request. Unlike Direct, this authentication mechanism prescribed the transmission format of credentials as well as their transmission medium. That is, the credential string was the username appended with a colon and concatenated with the password. The resulting string was then encoded using the Base64 algorithm. The Base64-encoded string was transmitted in the HTTP header to the server. Once it reached the server, the credentials were Base64-decoded, resulting in the colon-separated username and password string.
HTTPDigest
HTTPDigest described the authentication mechanism that followed the same process as the HTTP basic access mechanism but enhanced it by encrypting the credentials using the MD5 cryptographic hashing algorithm together with nonce values, i.e., a digest of the username and password that could not be directly decoded. Similar to HTTPBasic, it prescribed the transmission format as well as the transmission medium for the credentials.
OAuth
OAuth described the OAuth authentication mechanism, in which a User granted access to his/her protected resources, hosted by a Service Provider, to a Consumer Application without sharing credentials with the Consumer Application. To request access to protected resources, the Consumer Application used tokens generated by the Service Provider instead of the User’s credentials, such as username and password. The process used two token types, request token and access token, which were intermediary results of the OAuth process (also known as token acquisition dance) initiated by a request with only the Consumer Key and Consumer Secret as credentials. For Consumer Applications with single-user use cases, some Service Providers, like Twitter, offered the ability to issue an access token directly for the Consumer Application’s self-owned account without needing to implement the entire OAuth token acquisition dance. Instead, the Consumer Application could pick up from the point where it worked with an access token to make signed requests for Twitter resources. Also, for Service Providers that implemented OAuth to protect resources not belonging to a particular user, such as Yelp, the Consumer Application could obtain an access token directly at registration time. In these cases, the access token and access token secret became credentials required when the first request was raised to the Service Provider. The credentials involved in the OAuth process were described in classes of OAuthConsumerKey, OAuthConsumerSecret, OAuthToken, and OAuthTokenSecret, which were subclasses of the Credentials class. In a full OAuth dance, the Service Provider needed to expose three additional URLs: the request token URL, authorise URL, and access token URL, to the Consumer Application for obtaining request tokens, directing users to authorise, and obtaining access tokens, respectively. These URLs, though related to the Service Provider’s API, were more associated with the OAuth authentication mechanism than the API itself, and therefore were described by the authentication ontology. Specific to the OAuth type of authentication mechanism, it had three additional properties: hasRequestTokenURL, hasAuthorizeURL, and hasAccessTokenURL to aid in annotating OAuth-specific service properties.
WebAPIOperation
WebAPIOperation was used to describe cases where Web APIs implemented their operations, which needed to be called before being able to invoke other operations. Usual credentials like API Key, Username, and Password might have been required to call this particular operation. The number of Web APIs that used such an authentication mechanism was rather small, accounting for only 5% of our surveyed APIs.
SessionBased
SessionBased described the authentication mechanism where the user had to obtain a unique session key through a login service call, which took a username and password as credentials. The user then had to include the session key in each following request and make a logout call when finished. This type of authentication was not well suited for Web APIs because it required the API clients to keep track of the state and make a minimum of three HTTP requests to call just one operation. As reflected by our survey, only 2% of Web APIs used such an authentication mechanism.
Association of Authentication Ontology with Service Ontology
The authentication ontology was expected to serve the purpose of extending service description with authentication information by simply attaching it to the service and operation elements. One of the design principles, among many others, was to not be bound to any Web API description model, and hence the Service and Operation classes lacked a namespace because they served as placeholders that could be replaced by the service and operation elements of any Web API model, not necessarily the service ontology model proposed here. In this way, the ontology could be used as an extension to existing formalisms and remain independent of them. The extension of the authentication ontology to any service model was defined as follows: the Service class, of any service model, related to the ServiceAuthentication class through the requiresAuthentication property. This class had three instances: All, Some, and None, which were used to indicate that the service required authentication for all its operations, only some of them, or none of them. These properties could be explicitly defined or deduced through reasoning mechanisms over the operation annotations. The Service or Operation class had a relationship to the AuthenticationMechanism class through the hasAuthenticationMechanism property.
Team
Carlos Pedrinaci
Jacek Kopecky
Maria Maleshkova
Dong Liu
Publications
Maleshkova, M., Pedrinaci, C., Li, N., Kopecky, J. and Domingue, J. (2011) Lightweight Semantics for Automating the Invocation of Web APIs, IEEE International Conference on Service Oriented Computing & Applications (SOCA 2011), Irvine, California, USA.
Li, N., Pedrinaci, C., Kopecky, J., Maleshkova, M., Liu, D. and Domingue, J. (2011) Towards Automated Invocation of Web APIs, Poster at 8th Extended Semantic Web Conference.
Li, N., Pedrinaci, C., Maleshkova, M., Kopecky, J. and Domingue, J. (2011) OmniVoke:A Framework for Automating the Invocation of Web APIs, Fifth IEEE International Conference on Semantic Computing, Stanford University, Palo Alto, CA, USA.




