About
KnoFuss was a semantic data fusion system designed to resolve the data linking problem between two RDF-based semantic datasets. It addressed the challenge of identifying entities that referred to the same real-world object but were represented using different URIs. These entities were either merged (by replacing URIs) or linked using relations like owl:sameAs. This problem was comparable to the record linkage task in database research.
Main Features
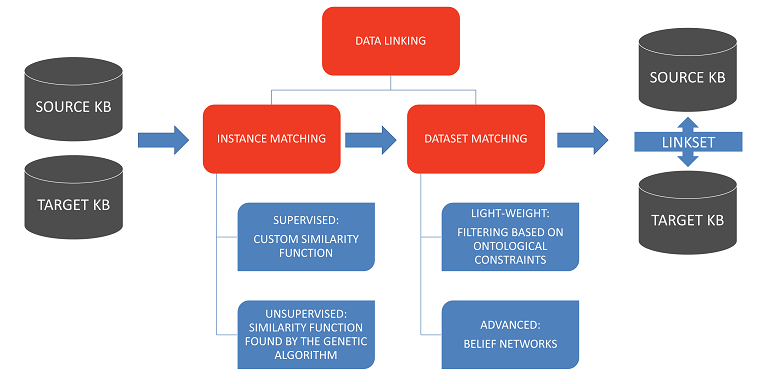
KnoFuss was built as a modular and extensible system using problem-solving methods. The data linking task was broken down into two key subtasks:
- Individual Matching – Compared properties of two individuals to determine whether they referred to the same entity.
- Dataset Matching – Analyzed and refined the candidate mappings from individual matching, taking into account ontological constraints and the impact of different mappings on each other.
The system supported multiple generic and domain-dependent methods for these subtasks. Techniques included string-based and set-based similarity metrics for individual matching, as well as ontological constraints and belief networks for dataset matching.
Methods Implemented
Individual Matching
- Aggregated Attribute-Based Similarity – Calculated the similarity between individuals by aggregating similarities between selected attributes. Users could define properties, similarity functions, weights, and thresholds.
- Unsupervised Attribute-Based Similarity – Used the same aggregation approach but automatically determined parameters through a genetic algorithm, optimizing results based on an expected distribution of mappings.
Dataset Matching
- Filtering Based on Ontological Constraints – Used constraints like class disjointness, functionality, and cardinality restrictions to refine and filter mappings generated by individual matching.
- Belief Propagation Network – Applied uncertainty reasoning alongside ontological reasoning to improve mappings. Confidence levels of data statements and mappings were interpreted as Dempster-Shafer belief functions. These were used to construct belief propagation networks, which helped refine individual matching decisions.
The system allowed different methods to be plugged in and combined, selecting the most appropriate approach depending on the task requirements.
KnoFuss addressed ontological heterogeneity in repositories by implementing several strategies to manage differences in ontology structure when dealing with overlapping data. These strategies included:
Unsupervised adaptation – In the absence of schema mappings, the system employed a genetic algorithm to identify and select pairs of discriminative properties that contained comparable data.
User-defined selection criteria – Users could specify how to select instances to compare from both repositories and which properties were comparable for individual matching.
Exploiting automatic ontology matching – The system could leverage schema alignments produced by automatic ontology matching tools. These alignments helped translate SPARQL queries, allowing instances and properties from different ontologies to be compared as if they were structured using the same ontology.




