About

CORDER (COmmunity Relation Discovery by named Entity Recognition) was an unsupervised machine learning algorithm that utilised named entity recognition and co-occurrence data to associate individuals in a community with their expertise and associates. It discovered relationships from community web pages by analyzing the co-occurrences of named entities (NEs) and the distances between them. The algorithm assumed that closely related NEs appeared together more frequently and in closer proximity on web pages. CORDER calculated a relation strength for each co-occurring NE based on their frequency and distance from the given NE, then ranked the co-occurring NEs by their relation strengths.
CORDER was supported by the Dot.Kom project, Stela Institute and the AKT project.
Team
Dr. Jianhan Zhu
Alexandre L. Goncalves
Dr. Victoria Uren
Prof. Enrico Motta
Prof. Roberto Pacheco
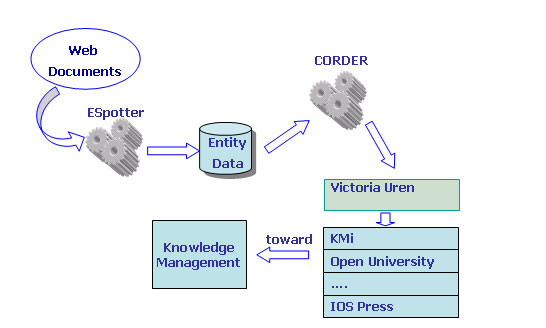
System Architecture
The architecture of CORDER was designed to support the system’s ability to discover and rank relationships within a community using named entities.
Publications
Zhu, J., (2007) Social Search With Missing Data: Which Ranking Algorithm?, Journal of Digital Information Management special issue on Web Information Retrieval, eds. Pit.Pichappan, Keith van Rijsbergen, and Iadh Ounis, Digital Information Research Foundation.
Zhu, J., Goncalves, A., Uren, V., Motta, E., Pacheco, R., Song, D. and Rueger, S. (2007) Community Relation Discovery by Named Entities, International Conference on Machine Learning and Cybernetics 2007, Hong Kong, China, IEEE.
Zhu, J., (2007) Relation Discovery from Web Data for Competency Management, Web Intelligence and Agent Systems: An International Journal, 5, 4, IOS Press.
Dzbor, M., Stutt, A., Motta, E. and Collins, T. (2007) Representations for semantic learning webs: Semantic Web technology in learning support, Journal of Computer Assisted Learning, 23, 1, pp. 69-82, Blackwell Publishing Ltd., UK.




