About

The Semantic Web vision aimed to provide rich, ontology-based semantic markup to enhance interoperability among agents and assist human users in locating and understanding information. The availability of semantic markup also enabled advanced question-answering systems. One key application of this was the AquaLog query-answering system, which was developed on the premise that the Semantic Web would benefit from natural language query interfaces, allowing users to query semantic markup as a knowledge base. This approach provided a new perspective on longstanding research challenges in natural language database (NLDB) systems.
AquaLog was a portable question-answering system that processed natural language queries and ontologies to retrieve answers from one or more knowledge bases. It was designed to be adaptable, as its architecture was independent of specific ontologies and knowledge representation systems. AquaLog could be configured for a particular ontology within minutes and used a modular, plug-in-based architecture to interact with ontologies through an OKBC-like protocol.
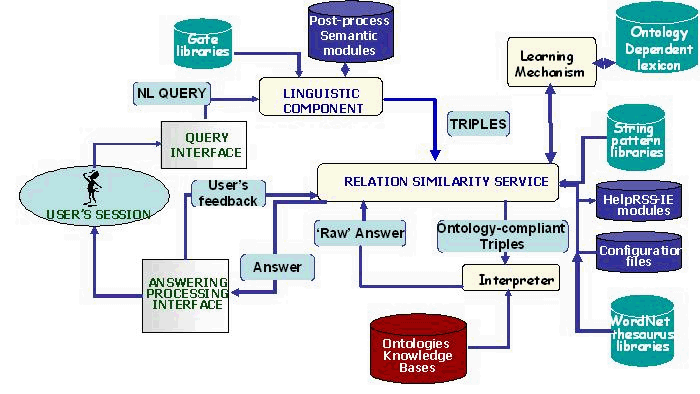
The system employed multiple strategies to process queries effectively. It incorporated the GATE NLP platform for linguistic processing, string metrics algorithms, and a learning mechanism to manage lexical resources, including domain-specific lexica and generic sources like WordNet. Additionally, AquaLog utilised an ontology-based relation similarity service to interpret user queries in relation to the target knowledge base.
Building on AquaLog, researchers developed PowerAqua, an advanced system designed to retrieve answers from any semantic document available on the Semantic Web, expanding the capabilities of natural language query processing.
Aqualog examples and limitations
AquaLog was designed to handle 16 main categories of queries based on linguistic criteria. Within each category, further analysis was conducted to identify subcategories or different methods for processing queries. This analysis considered both linguistic and ontological information. The ontology played a crucial role in reformulating and interpreting queries by identifying concepts, instances, values, and the relationships between them.
Aqualog approach and components
AquaLog’s core components were the Linguistic Component and the Relation Similarity Service (RSS). The Linguistic Component categorised and translated natural language queries into intermediate representations called Query-Triples. The RSS Component then processed these Query-Triples to generate ontology-compliant queries, referred to as Onto-Triples. AquaLog’s data model was based on triples.
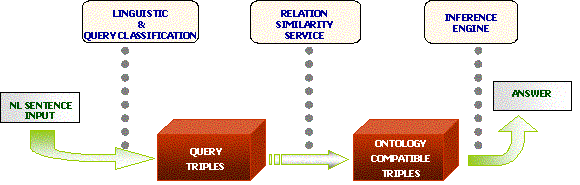
A key challenge in developing AquaLog was handling complex natural language queries, which often included multiple terms, explicit and implicit relations, and ambiguous mappings to ontology instances, classes, or values. Addressing linguistic ambiguity was a fundamental aspect of the system’s design.
AquaLog was developed as a portable and modular system, implemented in Java as a web application using a client-server architecture. It featured a plug-in mechanism, allowing it to be configured for different knowledge representation (KR) languages. Initially, AquaLog subscribed to the Operational Conceptual Modelling Language (OCML) using an OCML-based KR infrastructure, with plans to support RDF and OWL in the future.
To match query terms with ontology patterns, AquaLog employed string algorithms based on String Distance Metrics. It used an open-source implementation from Carnegie Mellon University, incorporating various metrics, including edit-distance, heuristic, token-based, and hybrid methods. After experimental comparisons with the KMi ontology, AquaLog adopted a combination of Jaro-Winkler, Level2 Jaro-Winkler, and Jaro metrics for name-matching tasks.
Evaluation
AquaLog employed an inference engine to process queries. For example, users could ask, “Which projects in KMi are related to the Semantic Web?” and receive precise answers based on reasoning over the semantic markup.
The system was evaluated through user testing, where participants asked questions within the academic KMi domain. AquaLog demonstrated the ability to handle a variety of query types, including Wh-queries, affirmative-negative questions, and complex queries with multiple relations. It also tolerated some spelling errors.
However, AquaLog had limitations. It did not support temporal reasoning, similarity or ranking-based queries, genitive structures, or complex multi-relation queries. Users were asked to provide feedback on their experience, including their level of domain expertise, usability perceptions, and suggested improvements.
Despite its limitations, AquaLog provided an interactive and intuitive way to query semantic data using natural language, making it a valuable tool for navigating structured knowledge bases.
Team
Vanessa Lopez
Enrico Motta
Victoria Uren
Marta Sabou
Michele Pasin
Vanessa Lopez
Anne de Roeck.
Harriett Cornish
Damian Dadswell
Kalina Bontcheva
Publications
AquaLog: An ontology-driven question answering system for organizational semantic intranets Lopez, V., Uren, V., Motta, E. and Pasin, M. (2007) , Journal of Web Semantics, 5, 2, pp. 72-105, Elsevier.
PowerMap: Mapping the Semantic Web on the Fly. Vanessa Lopez, Marta Sabou, Enrico Motta. In the proceedings of ESWC 2006 (European Semantic Web Conference), Montenegro.
PowerAqua: Fishing the Semantic Web. Vanessa Lopez, Enrico Motta, Victoria Uren. In the proceedings of ESWC 2006 (European Semantic Web Conference), Montenegro.
PowerAqua: An Ontology Question Answering System for the Semantic Web Ontologies and Web Semantic workshop. CAEPIA 2005 (XI conferencia de la asociacion espanola para la Inteligencia Artificial) Santiago de Compostela, Spain Vanessa Lopez, Enrico Motta.
AquaLog: An Ontology-portable Question Answering System for the Semantic Web. Vanessa Lopez, Michele Pasin, Enrico Motta. In the proceedings of ESWC 2005 (European Semantic Web Conference), Creete, Grece.
AquaLog 2 pages description for the demo session in EKAW 2004
Ontology Driven question answering in AquaLog. Vanessa Lopez, Enrico Motta. In the proceedings of NLDB 2004 (9th International Conference on Applications of Natural Language to Information Systems), Manchester, England. Published in the Book: AKT: Selected papers 2004




